大规模数据库整理有关人类蛋白质的信息
关于人体内的蛋白质如何协同工作还有很多东西需要理解; 然而,一种新开发的资源正在让科学家们更全面地了解蛋白质组如何使我们成为独一无二的人类。由Macquarie大学科学家领导的合作研究小组开发的MissingProteinPedia不仅可以帮助研究人员更多地了解体内特定蛋白质的位置和用途(称为“表达”),还可以了解它们如何相互作用以使我们成为人类。它还有助于确定那些仍处于阴影中的蛋白质,并对几种疾病产生影响。
“虽然我们对个体蛋白质有了很多了解,但是这些蛋白质如何协同工作以形成个体的更大图景是一个难以探索的概念。虽然我们正在开发新技术来测试蛋白质表达的时间,地点,原因和方式,我们仍然需要某种方式将所有生物信息联系在一起,以便我们更清楚地了解蛋白质如何协同工作以使我们成为一个人类,“缺失蛋白质研究的第一作者Mark Baker教授解释道。
“我们的团队开发了MissingProteinPedia来收集有关人类蛋白质组计划所谓的缺失蛋白质的所有分散和不完整的信息。这包括2,949种蛋白质,尽管经过严格的测试,仍处于”阴影中“并且尚未被证实存在,“ 他加了。
该工具加速了许多缺失蛋白质的发现,特别是那些难以捉摸的蛋白质家族,对人类疾病具有潜在的巨大影响。
“为了了解疾病如何进展,我们需要详细了解所有蛋白质如何在健康个体中发挥作用,以便我们能够了解导致疾病发展的因素,”资深作者Shoba Ranganathan教授解释说。
“MissingProteinPedia已经发现了许多难以检测的蛋白质的大量证据,其中少量信息需要多年才能收集。我们在如此短的时间内到目前为止这一事实预示着我们对复杂人类疾病的理解,例如作为癌症,“她补充道。
研究人员将使该数据库成为一个社区驱动的公民科学项目,每个人都可以帮助发现人类缺失的蛋白质及其在健康和疾病中的作用。
推荐内容
-
没有微生物毛毛虫没问题
微生物组似乎无处不在:人类和许多其他物种依赖其内脏的数十亿微生物来帮助消化,代谢和其他功能。现在,科罗拉多大学博尔德分校的科学...
-
细菌使用不同的策略在压力下分裂和生存
在实验室条件下,许多常见细菌繁殖并分成对称的一半。然而,在资源有限的现实世界中,条件并不总是理想的这种精心策划的增长。芝加哥大...
-
研究发现猫和狗食物中的草甘膦
有草甘膦吗?你的宠物早餐可能会。本月发表在康涅狄格州环境污染研究中的一项新研究发现,草甘膦是广泛使用的杂草杀手如Roundup中的活性除草
-
研究揭示了对“不朽”植物细胞的新见解
一项新研究揭示了一种未被发现的重编程机制,该机制允许植物保持适应世代。由冯小奇博士领导的John Innes中心团队在开花植物中研究生殖细
-
关于germlines如何恢复活力的可能解释
加利福尼亚大学和卡利科生命科学学院的一对研究人员发现了关于人类种系如何恢复活力的可能解释。在他们发表在Nature杂志上的论文中,Adam
-
研究揭示了在压力 衰老过程中如何改变产生健康心脏组织的遗传信息
弗吉尼亚理工大学Carilion的Fralin生物医学研究所的研究人员已经揭示了在压力和衰老过程中,身体中产生健康心脏组织的遗传信息如何被改变,
-
灰熊的策略可以帮助预防人类的肌肉萎缩
灰熊在冬眠中要花很多个月的时间,但是它们的肌肉不会因为缺乏运动而受苦。在迈克尔·戈特哈特(Michael Gotthardt)领导的团队的《科学报告
-
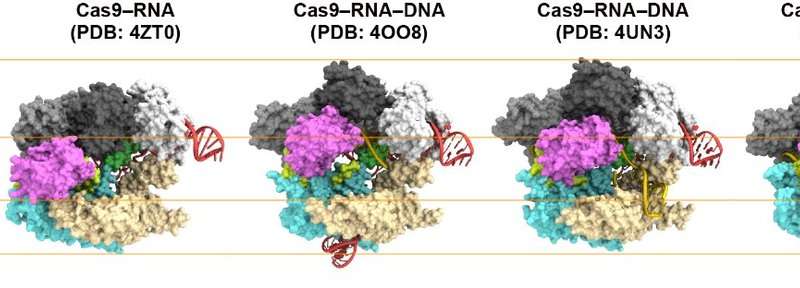
基因工程机制可视化
金泽大学和东京大学的研究人员在Nature Communications上报告了分子剪刀动力学的可视化 - 这是CRISPR-Cas9基因工程技术的主要机制。基因
-
12月13日绍兴隔离区疫情最新数据公布 昨日,绍兴累计报告本土
绍兴累计报告本土确诊病例107例 无症状感染者1例 均在市定点医院接受隔离治疗。12月12日晚,绍兴市在上虞区召开新冠肺炎疫情防控工作新闻
-
致命性附着 致病菌如何粘附在粘膜上并避免去角质
鼻,咽喉,肺,肠和生殖道中的粘液表面是许多病原体首次接触的点。作为一种防御策略,大多数动物(和人类)可以快速去除这些表面(即脱落表面